



这是系列的第 2 部分。如果您尚未构建核心管道,请从 Part 1 开始。它涵盖了顺序代理模式、共享状态和我们正在构建的 4 代理研究管道。您可以在 GitHub 上找到该项目的完整源代码。
在 Part 1 中,我们使用 ADK-TS 的顺序代理模式构建了一个研究助手:四个代理在一个严格的管道中运行,通过共享状态进行通信。
但 "可运行 "和 "可投入生产 "是两码事。
现在,我们的流水线正在静默运行。当我们等待大约 30-60 秒时,它就会启动,而我们根本不知道发生了什么。我们无法在不编辑代码的情况下配置这些行为。每个研究会话在完成后都会消失。以这种方式发布可能会感觉更快,但这种捷径很快就会变成技术债务。
在本指南中,我们将从 ADK-TS(TypeScript 人工智能代理框架)中添加四项功能,以弥补这些不足:
- Before/after 代理回调--因此您可以查看正在运行的步骤以及每个步骤所需的时间
- Before 工具回调--因此研究人员无法超过搜索限制、在框架级别强制执行
- 会话状态初始化--因此应用程序级别的配置存在于状态中,而不是硬编码在指令中
- 内存服务--因此已完成的研究会话会持续存在,并可跨会话进行搜索
每个功能都是独立的。您可以采用任何一项,而无需其他功能。它们共同使您的多代理系统具有可观察性、可配置性和有状态性。
TL;DR
- Agent 回调可让您记录进度、测量定时和有条件地跳过代理,而无需修改代理代码
- 工具回调强制执行硬搜索限制,并防止 LLM 在一个回合中批量调用多个工具
- 会话状态前缀对您的数据进行范围划分:
app:用于全局配置,user:用于每个用户的首选项,temp:用于短暂数据,unprefixed 用于管道输出 .withQuickSession()前加载状态,以便代理可在运行时通过模板语法读取配置值- MemoryService持久化已完成的会话,并使它们可在未来的运行中进行搜索(在开发中使用
InMemoryStorageProvider,在生产中使用持久化后端)
Prerequisites
本指南从第 1 部分开始。您应该具备:
- 第 1 部分中的 研究助手项目,以及正在运行的 4 代理管道
- 第 1 部分中的所有先决条件(Node.js 18+、API 密钥、熟悉 TypeScript)。如果您对人工智能代理完全陌生,本 使用 ADK-TS 构建 AI 代理的入门指南是一个很好的起点
- 对
outputKey和{state_key}模板如何工作有一个基本了解(在第 1 部分中有所涉及)
Understanding AI Agent Callbacks、状态和内存
在深入了解代码之前,让我们先了解一下每个功能的作用以及使用这些功能的原因。
AI 代理回调:用于日志记录和监控的生命周期钩子
现在,我们的管道静默运行。您启动它,等待 30-60 秒,最终得到一份报告,而中间发生了什么却无从知晓。每个 LlmAgent 都支持两个可选的回调:
beforeAgentCallback在代理处理其回合之前运行。它可用于日志记录、验证或有条件地跳过代理。afterAgentCallback在代理结束后运行。
两者都会接收包含 agentName, state (读/写)和 invocationId 的 CallbackContext 。返回值控制着接下来会发生什么:
- 返回
undefined以让回调的代理(它所连接的代理)继续正常执行。例如,如果beforeAgentCallback连接到分析员代理并返回undefined,分析员将照常运行其 LLM 调用。返回的内容将被用作代理的输出,然后管道将进入下一步。当代理的输出已存在于状态中时,这对于缓存或跳过代理非常有用。
由于回调与代理定义是分开的,因此您可以在所有四个代理中添加日志记录和监控,而无需触及它们的指令或逻辑。
Tool Callbacks:如何对人工智能代理工具调用进行评级限制
在第 1 部分中,研究员代理的说明中写道:"每轮只调用一次 web_search"。但说明只是建议,而不是规则。
工具回调在框架层面解决了这一问题。代理回调与 代理的生命周期挂钩,而 工具回调则与单个 工具调用挂钩:
beforeToolCallback在每次工具调用之前触发 。afterToolCallback在每次工具调用完成后触发。
beforeToolCallback接收工具、参数和工具上下文。返回值与代理回调类似:
- 返回
undefined以让工具正常执行。 - 返回
Record<string, any>以完全跳过工具。返回的对象将被发送回 LLM,就好像它是工具的实际响应一样。
这就是您如何强制执行无法通过提示工程绕过的硬限制。LLM 永远不会知道工具被阻止;它只是看到一个响应,告诉它下一轮再试一次。
AI 代理会话状态:使用关键前缀的作用域配置
在第 1 部分中,搜索次数等配置被硬编码在代理指令中。如果您想更改,则需要编辑代码。会话状态前缀为您提供了一个更好的选择,它允许您将配置存储在状态中,并对其进行适当的范围设置。
ADK-TS 通过键前缀支持四种状态范围:
前缀范围示例存在吗
| 前缀 |
|---|
app: 所有用户,所有会话(全应用程序)app:pipeline_steps是。 是 用户:一个用户的所有会话用户:首选模型是 <代码>temp:仅当前会话temp:researcher_agent_start否 (无)仅当前会话search_results是
前缀是键名的一部分,因此 app:pipeline_steps 和 pipeline_steps 是两个不同的键。代理可以在运行时使用其指令中的模板语法读取这些值,例如 {app:report_format},在 LLM 看到这些值之前,它们会被实际值替换。
AI 代理内存:如何跨会话保存数据
如果没有内存,每个研究会话都是一次性的。管道运行、生成报告以及所有中间数据(搜索结果、分析、建议)都会在会话结束时丢失。如果用户今天研究了 "医疗保健领域的人工智能",下周又研究了 "药物发现领域的人工智能",那么第二个会话就无法在第一个会话的基础上继续研究。
ADK-TS 的 MemoryService 通过存储已完成的会话并使其可被搜索来解决这一问题。流程如下:
- 运行管道。
- 在管道完成后,通过调用
memoryService.addSessionToMemory(session)保存到内存中。 - 稍后使用
memoryService.search({ query: "...", userId: "..." })进行搜索。这会根据关键字与存储内容的重叠程度返回匹配的会话。
MemoryService 需要一个存储提供程序。ADK-TS 随附的 InMemoryStorageProvider 会将所有内容保存在进程内存中。这对于开发和测试很好,但当应用程序重新启动时会重置。对于生产应用,您可以使用 PostgreSQL 等持久性后端来实现 MemoryStorageProvider 接口,或者使用 Pinecone 等向量存储来进行语义搜索。
如何为 TypeScript AI 代理添加回调、状态和内存
现在您已经了解了每个功能的作用,让我们将它们连接到第 1 部分中的研究助手。我们将完成五个步骤:创建回调函数、将它们附加到代理、添加工具级搜索限制、初始化会话状态以及连接内存服务。
Step 1: Create the Callbacks File
首先,创建一个共享的回调文件。两个回调使用相同的 STEP_LABELS 映射将代理名称翻译为人类可读的进度标签,并将定时数据存储在 temp: 状态中。
// src/callbacks.ts
import type { CallbackContext } from "@iqai/adk";
const STEP_LABELS:Record<string, string> = {
researcher_agent:"Step 1/4: Researcher"、
analyst_agent:"步骤 2/4:分析员"、
recommender_agent:"第 3/4 步:推荐人"、
writer_agent:"步骤 4/4:撰稿人"、
};
// 在临时状态下记录步骤名称和开始时间
export const beforeAgentCallback = async (ctx: CallbackContext) => {
const label = STEP_LABELS[ctx.agentName] ?
ctx.state[`temp:${ctx.agentName}_start`] = Date.now();
console.log(`\\\\n>>${label} - Starting...`);
返回未定义;
};
// 用持续时间记录完成情况
export const afterAgentCallback = async (ctx: CallbackContext) => {
const label = STEP_LABELS[ctx.agentName] ?
const startTime = ctx.state[`temp:${ctx.agentName}_start`] as
| 数字
| 未定义;
const duration = startTime
?((Date.now() - startTime)/ 1000).toFixed(1)
: "?";
console.log(`<<${label} - Complete (${duration}s)`);
返回未定义;
};
有两点需要注意:
temp:前缀在开始时间戳上意味着它不会被持久化到存储中。return undefined告诉 ADK-TS 让代理正常运行。
第 2 步:为每个代理附加回调
现在导入并为每个子代理附加回调。以下是分析员代理的示例。所有四个代理的模式都相同:
// src/agents/analysis-report-agent/agent.ts
import { LlmAgent } from "@iqai/adk";
import { env } from ".../../env";
import { STATE_KEYS } from ".../../constants";
// 导入回调以记录写入代理的开始时间和完成时间
import { beforeAgentCallback, afterAgentCallback } from ".../../callbacks";
export const getAnalysisAgent = () => {
return new LlmAgent({
name: "analyst_agent"、
description:
"分析原始研究数据以提取关键见解和模式"、
model: env.LLM_MODEL、
outputKey:state_keys.analysis_report、
beforeAgentCallback, // 已添加 beforeAgentCallback
afterAgentCallback, // 已添加 afterAgentCallback
disallowTransferToParent: true、
disallowTransferToPeers: true、
instruction: `...`, // 与第 1 部分相同
});
};
对所有四个代理执行同样的操作。
第 3 步:添加工具回调以执行搜索限制
这就是工具回调的作用所在。第 1 部分中的研究员代理被指示 "每轮只调用一次 web_search",但 LLM 并未可靠地遵循这一指示。
修复方法使用两个工具回调一起工作:
beforeToolCallback执行总搜索限制并防止并行批处理afterToolCallback在每次搜索完成后重置每轮标志
// src/agents/researcher-agent/agent.ts
从"@iqai/adk "导入 { LlmAgent, WebSearchTool };
import type { BaseTool, ToolContext } from "@iqai/adk";
import { env } from ".../../env";
import { STATE_KEYS, MAX_SEARCHES } from ".../../constants";
从".../.../callbacks "中导入 { beforeAgentCallback, afterAgentCallback };
// 执行搜索限制并防止并行工具调用
const enforceSearchLimit = async (
_tool:BaseTool、
_args:Record<string, any>、
toolContext:工具上下文
) => {
const count = (toolContext.state["temp:search_count"] as number) || 0;
if (count >= MAX_SEARCHES) {
返回 {
result: `达到搜索限制 (${MAX_SEARCHES}/${MAX_SEARCHES})。立即编译您的研究数据、
};
}
// 阻止并行工具调用 - 每个 LLM 响应一次搜索
if (toolContext.state["temp:search_in_progress"]) {
返回 {
result: `Only ONE search per turn.${count}/${MAX_SEARCHES} done.在下一个响应中再次搜索、
};
}
toolContext.state["temp:search_count"] = count + 1;
toolContext.state["temp:search_in_progress"] = true;
返回 undefined;
};
// 清除进行中标志,以便下一轮可以搜索
const clearSearchFlag = async (
_tool:BaseTool、
_args:Record<string, any>、
toolContext:ToolContext: 工具上下文、
_toolResponse:Record<string, any>;
) => {
toolContext.state["temp:search_in_progress"] = false;
返回未定义;
};
export const getResearcherAgent = () => {
return new LlmAgent({
name: "researcher_agent"、
// ...与第 1 部分的配置相同...
tools:[new WebSearchTool()]、
beforeAgentCallback、
afterAgentCallback、
beforeToolCallback: enforceSearchLimit, // 已添加 beforeToolCallback
afterToolCallback: clearSearchFlag, // 已添加 afterToolCallback
// ...指令与第 1 部分相同...
});
};
当模型尝试在一个响应中批量搜索 3 次时,会发生以下情况:
- 搜索 1:计数为 0,
search_in_progress为 false → 允许搜索,设置标志 - 搜索 2(并行):看到
search_in_progress = true→ 阻塞 - 搜索 3(并行):相同 → 受阻
- 搜索 1 完成 →
clearSearchFlag重置标志 - 下一个 LLM 轮:模型进行搜索 2(允许)
- 重复搜索 3
temp: 前缀确保这些计数器不会跨会话持久化。这种模式同样适用于您需要的任何工具限制:
Step 4:使用应用级配置初始化会话状态
到目前为止,我们的所有配置都存在于代码中。搜索限制是一个常数,管道步骤是在代理设置中定义的,用户或环境无法在运行时进行任何更改。我们可以通过在创建根代理时使用应用级配置预加载会话状态来改进这一点。这也将连接到我们之前介绍过的内存服务:
// src/agents/agent.ts
导入 {
AgentBuilder、
MemoryService, // 导入 MemoryService 以将其连接到生成器
InMemoryStorageProvider, // 导入 InMemoryStorageProvider 用于开发内存存储
从"@iqai/adk";
import { getResearcherAgent } from "./researcher-agent/agent";
import { getAnalysisAgent } from "./analysis-report-agent/agent";
import { getRecommenderAgent } from "./recommender-agent/agent";
import { getWriterAgent } from "./writer-agent/agent";
export const getRootAgent = async () => {
const researcherAgent = getResearcherAgent();
const analysisAgent = getAnalysisAgent();
const recommenderAgent = getRecommenderAgent();
const writerAgent = getWriterAgent();
// 使用用于开发的内存存储提供程序初始化内存服务
const memoryService = new MemoryService({
storage: new InMemoryStorageProvider()、
});
返回 (
AgentBuilder.create("research_assistant")
.withDescription(
"顺序研究流水线:研究→分析→推荐→撰写"
)
.asSequential([
研究者代理
analysisAgent、
推荐者代理
作家代理、
])
// 使用应用程序级配置和用户 ID 预加载会话状态,以便进行内存扩展
.withQuickSession({
appName:"research_assistant"、
userId: process.env.USER_ID ?"用户"、
state:{
"app:pipeline_steps":[
"研究员"、
"分析师
"推荐人
"作家"、
],
},
})
// 连接内存服务以实现跨代理的状态持久性
.withMemory(memoryService)
.build()
);
};
.withQuickSession() 创建一个预加载状态的会话。app:前缀意味着这些值是应用程序范围内的,所有用户和会话共享。
userId将user:前缀的状态和内存搜索范围限定为特定用户,因此一个用户的首选项和过去的研究不会泄漏到另一个用户。
.withMemory(memoryService) 将内存服务连接到构建器,以便存储和搜索已完成的会话。
步骤 5:为跨会话持久性添加内存服务
最后,更新 src/index.ts 以将所有内容连接在一起。这将演示读取会话状态、运行管道(使用回调记录进度)、将完成的会话保存到内存中以及搜索会话:
// src/index.ts
import * as dotenv from "dotenv";
import { MemoryService, InMemoryStorageProvider } from "@iqai/adk";
import { getRootAgent } from "./agents/agent";
dotenv.config();
async function main() {
const { runner, session }= await getRootAgent();
const memoryService = new MemoryService({
storage: new InMemoryStorageProvider()、
});
console.log("==============================");
console.log(" 研究助理管道");
console.log("==============================\\\\n");
console.log("Session state (app-level config):");
console.log(
app:pipeline_steps =${JSON.stringify(session.state["app:pipeline_steps"])}`); console.log(
);
console.log();
const topic = "2025 年人工智能对医疗保健的影响";
console.log(`Research topic: "${topic}"\\\\n`);
console.log("Starting sequential pipeline...\\\\n");
try {
const result = await runner.ask(topic);
console.log("\\\\n" + "=".repeat(50));
console.log(" 最终报告");
console.log("=".repeat(50) + "\\\\n");
console.log(result);
// 将会话保存到内存中,以便将来调用
await memoryService.addSessionToMemory(session);
console.log("\\\\nResearch session saved to memory.");
// 搜索过去的研究
const memories = await memoryService.search({
appName:"research_assistant"、
userId: process.env.USER_ID ?"用户"、
query: topic、
});
console.log(`Found${memories.length} stored session(s).`);
} catch (error) {
console.error("Error running research pipeline:", error);
}
}
main().catch(console.error);
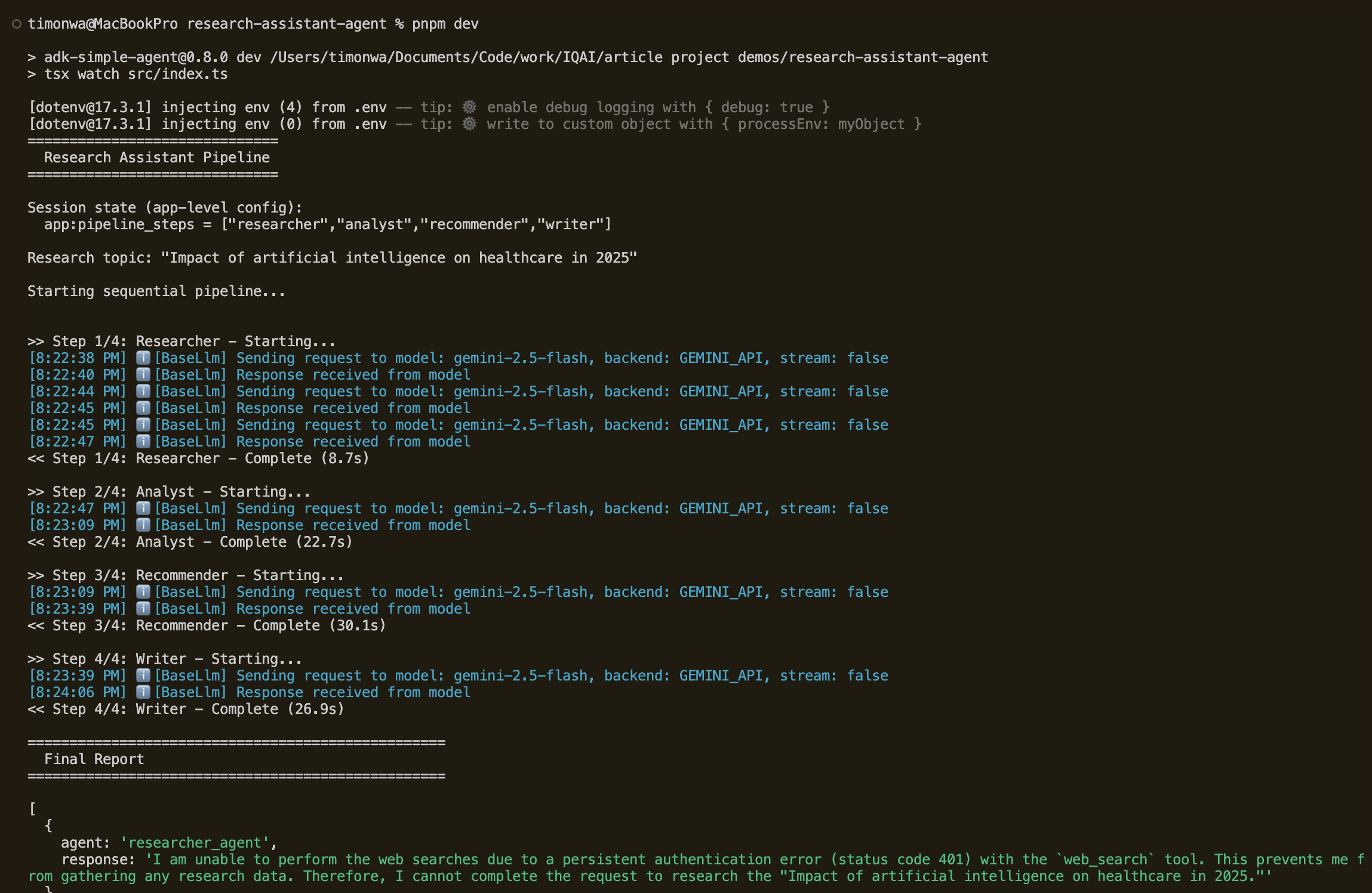
运行 pnpm dev 以执行管道。您将看到代理回调随着管道的进行,定时记录每个步骤的开始和完成。最后,内存服务会确认会话已保存并可搜索。

Conditionally Skip Steps in a Multi-Agent Pipeline
您可以使用 beforeAgentCallback 检查状态中是否已经存在有效输出,并完全跳过代理。这本质上是代理级缓存。如果前一个会话已经分析了这个主题,为什么还要再次运行分析器?
// src/callbacks.ts
export const skipIfDataExists = async (ctx: CallbackContext) => {
const existingReport = ctx.state["analysis_report"];
if (existingReport) {
console.log(`Skipping${ctx.agentName}, data already exists`);
return { parts: [{ text: existingReport }] };
}
return undefined;
};
Layer State Prefixes for Multi-Tenant Apps
您可以使用所有四个前缀级别来区分关注点:app:用于全局配置,user:用于每个用户的首选项,而会话范围的键则用于管道数据。
Persist AI Agent Memory in Production
InMemoryStorageProvider对于开发来说没有问题,但在某些时候,您会希望研究能够在重启后继续运行。使用 PostgreSQL 或 MongoDB 实现 MemoryStorageProvider 或使用向量存储,如 Pinecone 或 pgvector 进行语义搜索。这样,即使用户的查询与存储内容不完全匹配,也能找到过去的研究。
Integrate AI Agent Callbacks with OpenTelemetry
Our callbacks use console.log, which is fine for development but doesn't scale.
Integrate AI Agent Callbacks with OpenTelemetry
Our callbacks use console.log, which is fine for development but doesn't scale.
我们的回调使用 console.log, 这对开发很好,但不能扩展。ADK-TS通过OpenTelemetry集成提供了内置的可观察性,包括分布式跟踪、指标收集和开箱即用的自动仪表。
它可与 Jaeger、Grafana、Datadog 等平台以及任何OTLP 兼容的后端配合使用。将回调中的 console.log 调用替换为遥测跨度和指标,以构建每个代理的延迟仪表板、启用错误跟踪并捕获执行跟踪。OpenTelemetry 还在定义生成式人工智能系统的语义约定,它规范了代理框架报告跟踪、指标和日志的方式。
结论
有了这些新增功能,您的研究助手将从一个工作演示变为更接近生产就绪的产品:
- 回调可让您了解管道运行时发生的情况:哪个步骤处于活动状态、每个步骤需要多长时间,以及有条件跳过步骤的能力
- 会话状态前缀可将配置与数据分开。应用程序范围的设置使用
app:,临时数据使用temp:,而管道输出则使用会话作用域键。- ADK-TS Documentation:涵盖代理、状态、回调和内存的官方框架文档
- ADK-TS GitHub 仓库:源代码、问题和讨论
- ADK-TS 示例仓库:更多示例项目
- 介绍适用于 TypeScript 的代理开发工具包 (ADK):ADK-TS 及其设计目标概述
- 如何为 AI 代理添加持久性和长期内存:深入了解跨框架的内存模式
内存服务使研究具有持久性和可搜索性,从而将您的助手从一个无状态工具转变为一个不断增长的知识库。Part 1 中的顺序流水线与这些框架功能相结合,为您在 TypeScript 中构建可投入生产的多代理系统奠定了坚实的基础。完整的源代码可在 GitHub 上获得,并且与教程完全匹配,因此您可以一步一步地学习。您还可以在 ADK-TS Samples Repository 中找到该代理,随着框架的发展,其中可能会包含更新的版本。如需了解更多模板,请查看 ADK-TS x402 代理模板,该模板用于加密支付代理。欢迎向这两个软件仓库投稿。
Useful Resources
常见问题
人工智能代理框架中的回调是什么?
回调是生命周期钩子,可让您在代理管道中的关键事件(如代理开始轮转或工具被调用)前后运行自定义代码。它们对于添加日志、验证、速率限制或条件逻辑非常有用,而无需修改代理的核心行为。在 ADK-TS 中,这些回调分别是 beforeAgentCallback, afterAgentCallback, beforeToolCallback 和 afterToolCallback, 每个回调都会接收有关当前代理、会话状态和调用的上下文。
如何监控和记录 AI 代理的执行?
大多数代理框架都支持在代理开始和结束时触发的生命周期钩子。您可以使用这些钩子来记录进度、记录时间戳并计算每个步骤所需的时间。例如,beforeAgentCallback 和 afterAgentCallback 涉及代理级监控,而 afterToolCallback 可让您记录单个工具调用及其结果。对于生产,您将把这些指标发送到可观察性平台,而不是记录到控制台。
如何对人工智能代理工具调用进行速率限制?
最可靠的方法是在框架级别拦截工具调用,而不是依赖于提示指令。在临时状态中使用带有计数器或 "进行中 "标志的 before-tool 钩子。当工具调用进来时,检查计数器。如果计数器超过限制,则返回覆盖响应,而不是执行工具。
What is session state in AI agents, and how does it-work?
Session state 是一个共享的键值存储,代理可在管道运行期间读取和写入该存储。这是代理在不直接耦合的情况下相互传递数据的方式。一种常见的模式是使用键前缀来区分应用程序范围的配置(app:)、每个用户的偏好设置(user:)、短暂数据(temp:)和会话范围的管道输出(无前缀)。
What is the difference between short-term and long-term-ai-agent-memory?
短期内存是代理在单次对话或管道运行期间使用的工作数据,通常存储在会话状态中。长期记忆会跨会话持续存在,以可搜索的格式存储过去的对话,这样代理就能回忆起以前的工作,避免重复任务,或以以前的发现为基础。
如何让人工智能代理记住过去的对话?在管道结束后,将会话(包括所有累积的状态)保存到存储后端。在以后的会话中,您可以通过主题或关键字搜索该存储,以检索相关的过去工作。
大多数框架都提供了类似 addSessionToMemory() 的功能来保存会话,以及 search() 的功能来查询会话。
如何在运行时配置人工智能代理行为而不更改代码?代理运行时,模板将被状态中的实际值取代。这样,您就可以根据每个用户、每个请求或每个环境更改行为,而无需触及代理代码。
例如,您可以在状态中将 app:report_length 设置为 "brief",而包含 {app:report_length} 的指令将在运行时解析为 brief。
如何有条件地跳过多代理人工智能流水线中的步骤?
使用 before-agent 钩子检查代理的工作是否已经完成,例如,在状态中查找现有的输出。如果存在输出,则直接从钩子返回,而不是让代理运行。
例如,使用 beforeAgentCallback 时,返回 Content 对象将完全跳过代理。
如何调试多代理人工智能系统?
首先,在每个代理完成后记录完整的会话状态。这将准确显示每个代理生成了哪些数据,以及下游代理是否获得了它们所期望的输入。
诊断性 afterAgentCallback 可在每个步骤后转储状态,从而使设置变得简单。
What is the best way to store AI agent memory in production?
内存存储适用于开发,但会在应用重启时重置。对于生产,请使用持久性后端。流行的选择包括用于结构化存储的 PostgreSQL、用于快速访问的 Redis 或用于对过往对话进行语义搜索的向量数据库(如 Pinecone 或 Weaviate)。
正确的选择取决于您需要精确的关键字检索还是基于相似性的搜索。大多数框架都允许您通过实现一个标准接口来更换存储提供商,因此您可以从最简单的解决方案开始,然后在不更改代理代码的情况下进行升级。


